Massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning
Massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning
Massive Multitask Language Understanding (MMLU): How Large Language Models Are Evaluated
Introduction
Evaluating large language models (LLMs) requires more than checking whether they can generate fluent text. We need structured benchmarks that test reasoning, factual knowledge, and subject diversity. One of the most widely used benchmarks for this purpose is MMLU (Massive Multitask Language Understanding).
MMLU measures how well a model performs across a wide range of academic and professional subjects using multiple-choice questions.
What is MMLU?
MMLU is a benchmark designed to evaluate a model’s general knowledge and reasoning ability across diverse domains. It includes questions from subjects such as:
flowchart LR
INPUT(["User intent"])
PARSE["Parse plus<br/>classify"]
PLAN["Plan and tool<br/>selection"]
AGENT["Agent loop<br/>LLM plus tools"]
GUARD{"Guardrails<br/>and policy"}
EXEC["Execute and<br/>verify result"]
OBS[("Trace and metrics")]
OUT(["Outcome plus<br/>next action"])
INPUT --> PARSE --> PLAN --> AGENT --> GUARD
GUARD -->|Pass| EXEC --> OUT
GUARD -->|Fail| AGENT
AGENT --> OBS
style AGENT fill:#4f46e5,stroke:#4338ca,color:#fff
style GUARD fill:#f59e0b,stroke:#d97706,color:#1f2937
style OBS fill:#ede9fe,stroke:#7c3aed,color:#1e1b4b
style OUT fill:#059669,stroke:#047857,color:#fff
Mathematics
Computer Science
Physics
Law
Medicine
History
Economics
Philosophy
The benchmark spans dozens of subject areas, making it a strong indicator of broad intelligence rather than narrow specialization.
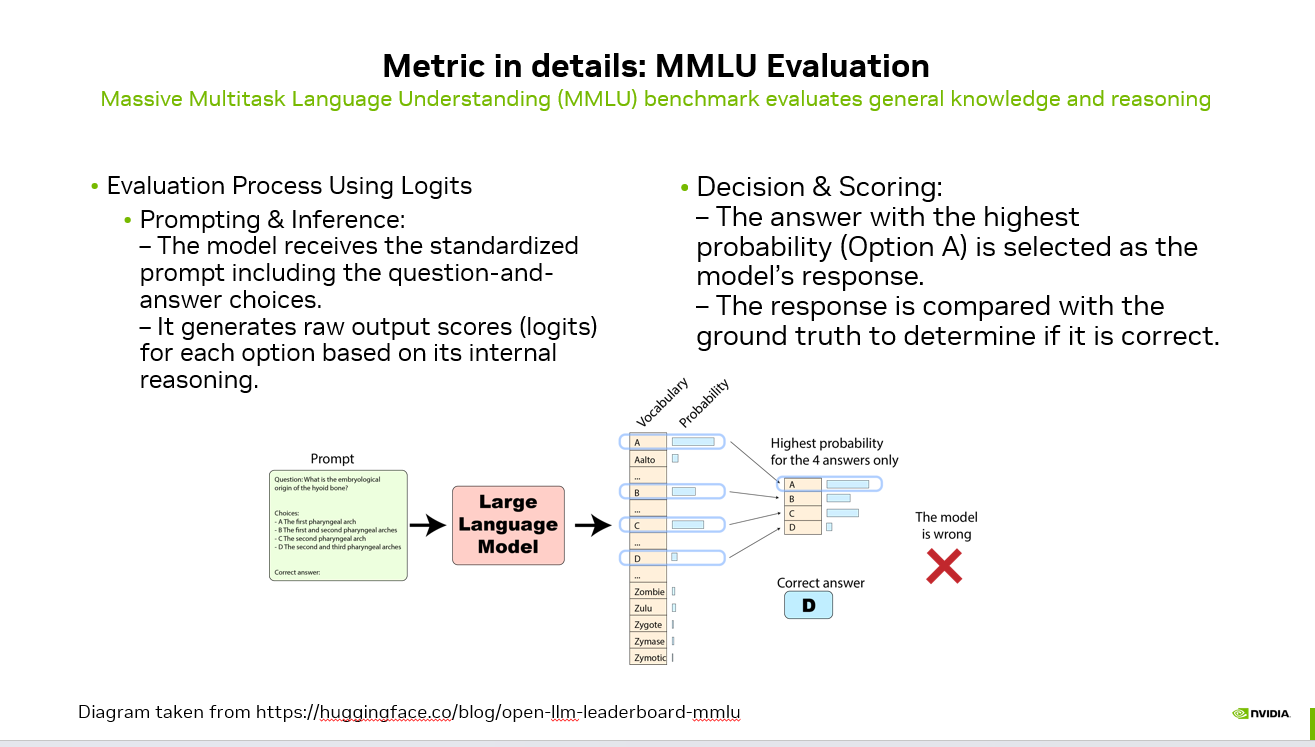
How the MMLU Evaluation Process Works
1. Prompting the Model
The model receives a standardized prompt that includes:
A question
Four answer choices (A, B, C, D)
Example format:
Question: What is X?
A) Option 1
B) Option 2
C) Option 3
D) Option 4
The correct answer is known beforehand (ground truth), but the model does not see it.
2. Logits Generation
Instead of directly outputting the final answer, the model internally produces logits.
Hear it before you finish reading
Talk to a live CallSphere AI voice agent in your browser — 60 seconds, no signup.
Logits are raw, unnormalized scores representing how likely each answer choice is according to the model.
For example:
OptionLogit ScoreA2.3B1.1C0.4D3.2
These logits are then converted into probabilities using a softmax function.
3. Decision Rule
The evaluation system selects the answer with the highest probability.
If option D has the highest probability, the model’s prediction becomes:
Predicted Answer: D
4. Scoring
The predicted answer is compared with the correct answer (ground truth).
If they match → the model gets 1 point.
If they do not match → the model gets 0 points.
Accuracy is calculated as:
Accuracy = (Number of Correct Answers / Total Questions) × 100%
Why Logits-Based Evaluation Matters
Using logits ensures:
Objective comparison
No reliance on verbose explanations
Consistent scoring across models
Reproducible evaluation methodology
This prevents ambiguity in answer interpretation and focuses strictly on measurable performance.
What MMLU Actually Measures
MMLU evaluates:
Factual knowledge
Multi-step reasoning
Domain transfer ability
Generalization across subjects
It does not measure:
Creativity
Open-ended writing quality
Long-form coherence
Still reading? Stop comparing — try CallSphere live.
CallSphere ships complete AI voice agents per industry — 14 tools for healthcare, 10 agents for real estate, 4 specialists for salons. See how it actually handles a call before you book a demo.
Conversational ability
Thus, MMLU is a strong academic reasoning benchmark, but not a complete measure of intelligence.
Strengths of MMLU
Broad subject coverage
Standardized multiple-choice format
Easy comparison between models
Clear, interpretable scoring (accuracy-based)
Limitations of MMLU
Multiple-choice structure may allow guessing
Does not evaluate long-form reasoning depth
Limited real-world task simulation
May favor models trained on similar datasets
Why MMLU Is Important in AI Research
MMLU has become a common benchmark in research papers and model leaderboards. High performance on MMLU indicates that a model has:
Strong knowledge representation
Effective reasoning capability
Cross-domain understanding
Because it spans many disciplines, it is considered a good proxy for general academic intelligence.
Final Thoughts
MMLU provides a structured and objective way to evaluate large language models across a wide range of subjects. By using logits-based decision making and strict accuracy scoring, it ensures consistent benchmarking across models.
However, while MMLU is powerful, it should be combined with other benchmarks to fully evaluate reasoning, creativity, safety, and real-world performance.
In modern AI evaluation pipelines, MMLU remains one of the foundational benchmarks for assessing general knowledge and reasoning strength.
#MMLU #MassiveMultitaskLanguageUnderstanding #LLMEvaluation #ArtificialIntelligence #MachineLearning #LargeLanguageModels #AIResearch #ModelBenchmarking #DeepLearning #GenerativeAI
Massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning — operator perspective
Practitioners building massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning keep rediscovering the same trade-off: more autonomy means more surface area for things to go wrong. The art is giving the agent enough room to be useful without giving it room to spiral. That contract is what separates a demo from a production system. CallSphere learned this the expensive way while wiring 37 specialized agents to 90+ tools across 115+ database tables — every integration that didn't enforce schemas at the tool boundary eventually paged someone.
Why this matters for AI voice + chat agents
Agentic AI in a real call center is a different beast than a single-LLM chatbot. Instead of one model answering one prompt, you orchestrate a small team: a router that decides intent, specialists that own a vertical (booking, intake, billing, escalation), and tools that read and write to the same Postgres your CRM trusts. Hand-offs are where most production bugs hide — when Agent A passes context to Agent B, anything that isn't explicit in the message gets lost, and the user feels it as the agent "forgetting." That's why the systems that hold up under load are the ones with typed tool schemas, deterministic state stored outside the conversation, and a hard ceiling on tool calls per session. The cost story is just as important: a multi-agent loop can quietly burn 10x the tokens of a single-LLM design if you let it think out loud at every step. The fix isn't a smarter model, it's smaller agents, shorter prompts, cached system messages, and evals that fail the build when p95 latency or per-session cost regresses. CallSphere runs this pattern across 6 verticals in production, and the rule has held every time: the agent you can debug in five minutes will out-survive the agent that's "smarter" on a benchmark.
FAQs
Q: Why does massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning need typed tool schemas more than clever prompts?
A: Scaling comes from constraint, not capability. The deployments that hold up keep each agent narrow, cap tool calls per turn, cache the system prompt, and pin a smaller model for routing while reserving the larger model for synthesis. CallSphere's stack — 37 agents · 90+ tools · 115+ DB tables · 6 verticals live — is sized that way on purpose.
Q: How do you keep massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning fast on real phone and chat traffic?
A: Hard ceilings beat heuristics. A maximum step count, an idempotency key on every tool call, and a fallback to a deterministic script when confidence drops below a threshold are what keep the loop bounded. Evals that simulate noisy inputs catch the rest before they reach a real caller.
Q: Where has CallSphere shipped massive Multitask Language Understanding (MMLU) benchmark evaluates general knowledge and reasoning for paying customers?
A: It's already in production. Today CallSphere runs this pattern in Salon and Healthcare, alongside the other live verticals (Healthcare, Real Estate, Salon, Sales, After-Hours Escalation, IT Helpdesk). The same orchestrator code path serves voice and chat — the difference is the tool set the router exposes.
See it live
Want to see salon agents handle real traffic? Spin up a walkthrough at https://salon.callsphere.tech or grab 20 minutes on the calendar: https://calendly.com/sagar-callsphere/new-meeting.
Try CallSphere AI Voice Agents
See how AI voice agents work for your industry. Live demo available -- no signup required.