What is Controlled Evaluation for Large Language Models?
By Sagar Shankaran, Founder of CallSphere
Assessing LLM Performance: Strategies to Evaluate and Improve Your App.
Key takeaways
In today’s AI race, most teams optimize for impressive demos.
Very few optimize for measurable performance.
If you’re building AI-powered products, controlled evaluation is not optional — it’s your competitive advantage.
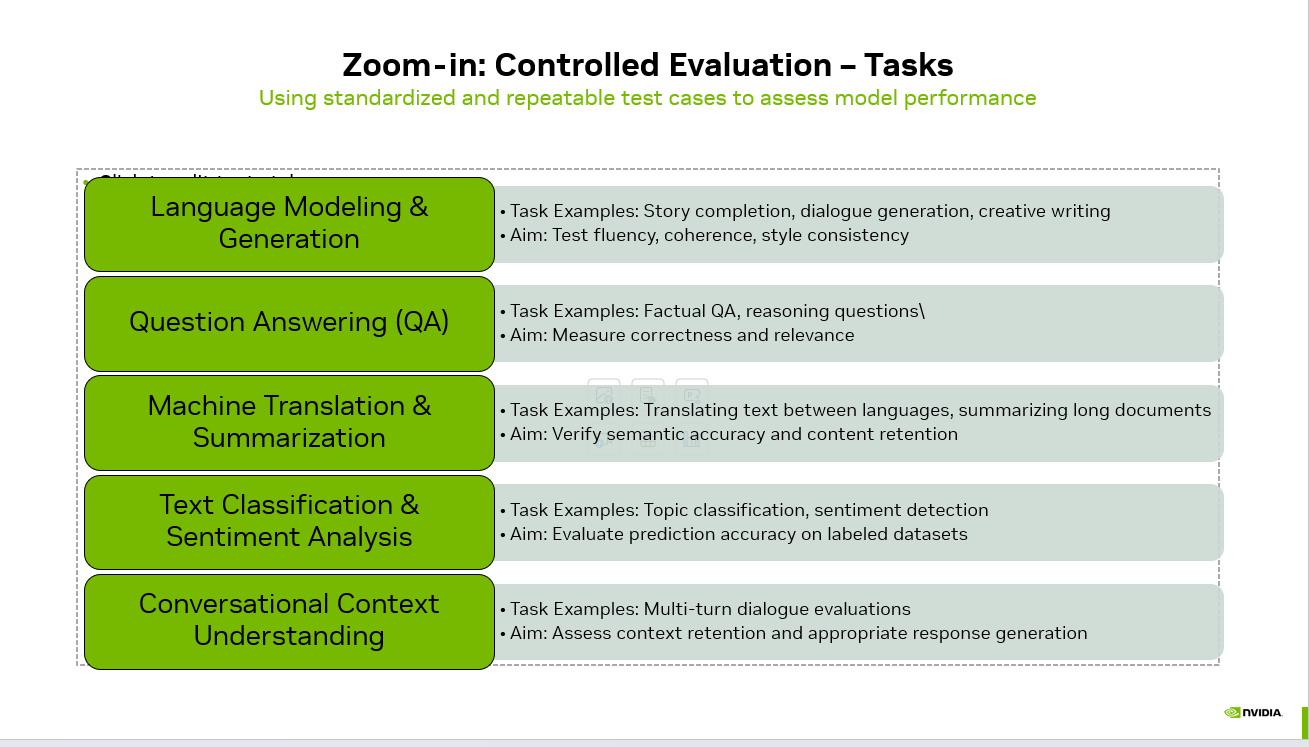
Controlled evaluation means using standardized, repeatable test cases to assess model performance across clearly defined tasks. Instead of relying on subjective judgment (“it sounds good”), you measure structured outcomes.
Let’s break down the core task categories every serious AI team should evaluate.
1️⃣ Language Modeling & Generation
Task Examples:
Story completion
Dialogue generation
Creative writing
What You’re Testing:
Fluency
Coherence
Style consistency
Creative generation often looks impressive in demos. But in production, you need consistency. Can the model maintain tone across 1,000 outputs? Does it drift stylistically? Does it hallucinate details?
Controlled prompts + scoring rubrics = measurable creativity.
2️⃣ Question Answering (QA)
Task Examples:
flowchart LR
PR(["PR opened"])
UNIT["Unit tests"]
EVAL["Eval harness<br/>PromptFoo or Braintrust"]
GOLD[("Golden set<br/>200 tagged cases")]
JUDGE["LLM as judge<br/>plus regex graders"]
SCORE["Aggregate score<br/>and per slice"]
GATE{"Score regress<br/>more than 2 percent?"}
BLOCK(["Block merge"])
MERGE(["Merge to main"])
PR --> UNIT --> EVAL --> GOLD --> JUDGE --> SCORE --> GATE
GATE -->|Yes| BLOCK
GATE -->|No| MERGE
style EVAL fill:#4f46e5,stroke:#4338ca,color:#fff
style GATE fill:#f59e0b,stroke:#d97706,color:#1f2937
style BLOCK fill:#dc2626,stroke:#b91c1c,color:#fff
style MERGE fill:#059669,stroke:#047857,color:#fff
Factual question answering
Multi-step reasoning questions
What You’re Testing:
Hear it before you finish reading
Talk to a live CallSphere AI voice agent in your browser — 60 seconds, no signup.
Correctness
Relevance
Logical consistency
This is where hallucinations become visible.
Benchmarking factual accuracy and reasoning depth under controlled inputs helps identify whether your system is reliable enough for customer-facing use cases.
3️⃣ Machine Translation & Summarization
Task Examples:
Translating text between languages
Summarizing long-form documents
What You’re Testing:
Semantic accuracy
Content retention
Information compression quality
It’s easy for a model to sound fluent while subtly changing meaning. Evaluation frameworks ensure the output preserves intent and key details.
4️⃣ Text Classification & Sentiment Analysis
Task Examples:
Topic classification
Sentiment detection
What You’re Testing:
Prediction accuracy
Precision / recall
Robustness across edge cases
Here, LLMs can be compared against traditional ML baselines. Controlled datasets allow objective performance comparisons.
5️⃣ Conversational Context Understanding
Task Examples:
Multi-turn dialogue evaluation
Context carryover tests
Still reading? Stop comparing — try CallSphere live.
CallSphere ships complete AI voice agents per industry — 14 tools for healthcare, 10 agents for real estate, 4 specialists for salons. See how it actually handles a call before you book a demo.
What You’re Testing:
Context retention
Response appropriateness
Instruction adherence
This is critical for AI agents and enterprise assistants. Many systems perform well in single-turn prompts but degrade across longer interactions.
Why This Matters
Without controlled evaluation:
You can’t compare models objectively.
You can’t measure improvements.
You can’t justify production deployment decisions.
You can’t build trust with stakeholders.
With controlled evaluation:
You move from opinion to metrics.
From demo-driven to data-driven.
From experimentation to engineering discipline.
The future of AI development won’t be decided by who builds the flashiest demo.
It will be decided by who measures performance rigorously and improves systematically.
If you're building with LLMs in 2026, ask yourself:
👉 Do you have a structured evaluation pipeline — or just impressive screenshots?
#AI #LLM #ArtificialIntelligence #MachineLearning #AIEngineering #GenAI #ModelEvaluation #DataDriven #AIProductDevelopment
What is Controlled Evaluation for Large Language Models? — operator perspective
What is Controlled Evaluation for Large Language Models? matters less for the headline than for what it forces operators to re-examine in their own stack — eval gates, fallback routing, and tool-call latency budgets. The CallSphere stack treats announcements as input to an evals queue, not a product roadmap. Production agents stay pinned; new releases earn their slot only after a regression suite confirms cost, latency, and tool-call reliability move the right way.
Base model vs. production LLM stack — the gap that costs you uptime
A base model is a checkpoint. A production LLM stack is a whole different artifact: eval gates that fail the build on regression, prompt caching that cuts repeated-system-prompt cost by 40-70%, structured outputs that prevent JSON drift on tool calls, fallback chains that route to a smaller-model retry when the primary times out, and request-side guardrails that cap tool calls per session before the loop spirals. CallSphere runs LLMs in tandem on purpose: gpt-4o-realtime for the live call (streaming audio in and out, tool calls inline) and gpt-4o-mini for post-call analytics (sentiment scoring, lead qualification, summary generation, and the lower-stakes async work that doesn't need realtime). That split is not a cost optimization — it's a reliability decision. Realtime is optimized for low-latency turn-taking; mini is optimized for cheap, deterministic batch scoring. Mixing them lets each do what it's good at without one regressing the other. The teams that struggle with LLMs in production almost always made the same mistake: they treated "the model" as a single dependency, instead of as a small portfolio of models, each pinned to a job, each behind its own eval suite, each with a documented fallback.
FAQs
Q: Why isn't what is Controlled Evaluation for Large Language Models? an automatic upgrade for a live call agent?
A: Most of the time it doesn't, and that's the right starting assumption. The relevant test is whether it improves at least one of: p95 first-token latency, tool-call argument accuracy on noisy inputs, multi-turn handoff stability, or per-session cost. Healthcare deployments use 14 vertical-specific tools alongside post-call sentiment scoring and lead-quality classification.
Q: How do you sanity-check what is Controlled Evaluation for Large Language Models? before pinning the model version?
A: The eval gate is unsentimental — a regression suite that simulates real call traffic (noisy ASR, partial inputs, tool-call timeouts) measures four numbers, and a candidate has to win on three of four without losing badly on the fourth. Anything else is treated as a blog post, not a stack change.
Q: Where does what is Controlled Evaluation for Large Language Models? fit in CallSphere's 37-agent setup?
A: In a CallSphere deployment, new model and API capabilities land first in the post-call analytics pipeline (lower stakes, async, easy to roll back) and only later in the live realtime path. Today the verticals most likely to absorb new capability first are Healthcare and IT Helpdesk, which already run the largest share of production traffic.
See it live
Want to see after-hours escalation agents handle real traffic? Walk through https://escalation.callsphere.tech or grab 20 minutes with the founder: https://calendly.com/sagar-callsphere/new-meeting.
Written by
Sagar Shankaran· Founder, CallSphere
Sagar Shankaran is the founder of CallSphere, where he builds production AI voice and chat agents deployed across healthcare, hospitality, real estate, and home services. He writes about agentic AI, LLM engineering, and shipping voice agents that handle real calls in production.
Try CallSphere AI Voice Agents
See how AI voice agents work for your industry. Live demo available -- no signup required.